2022.11.30
シリーズ勉強会「デジタル・フォレンジック鑑定と向き合うために」第1回レポート【犯罪学研究センター主催】
司法におよぶ情報処理
龍谷大学 犯罪学研究センター(CrimRC)は、デジタル・フォレンジック鑑定をテーマに、2022年11月19日、公開勉強会・シリーズ「デジタル・フォレンジック鑑定と向き合うために」第1回をオンラインで共催しました。本企画には約70名が参加しました。進行は、古川原明子教授(法学部/犯罪学研究センター「科学鑑定」ユニット長)がつとめました。
【イベント情報:https://www.ryukoku.ac.jp/nc/event/entry-11506.html】
当日の司会進行
はじめに
インターネットが普及して便利になった反面、インターネット上の犯罪(以下、サイバー犯罪)が増加しています。サイバー犯罪は誰もが被疑者にも被害者にもなりうる犯罪です。サイバー犯罪の捜査で警察は、デジタル証拠(デジタル・フォレンジックで鑑定された証拠)を収集します。こうした現状については未だ広く知られていません。そこで、デジタル証拠についてどう向き合うのか、どう理解するのか、今回5回シリーズの勉強会を企画しました。

平岡義博氏
情報技術の司法への適用
現在の情報化社会では、あらゆる地域から各家庭のあらゆる年齢層まで情報機器が浸透しており、犯罪形態も多様化しています。コンピュータウィルス、ネットを介した詐欺、人権侵害、仮想通貨の搾取などの犯罪はサイバー犯罪と呼ばれます。サイバー犯罪ではデジタル証拠が収集されます。このデジタル証拠は電磁記録媒体(PC、携帯電話、防犯カメラなど)に記録された情報で、画像記録、通話記録、通行記録などさまざまです。一方、これまでの科学鑑定では人間の目で見た形態比較鑑定試料を主観的に鑑定してきましたが、デジタル・フォレンジック鑑定では、コンピューター技術を使った方法で顔画像や声紋、筆跡などの形態比較鑑定試料を鑑定されるようになってきました。このようにして提出されたデジタル証拠は最終的に、裁判において法律家が審議することになります。ここで問題になるのがデジタル証拠の理解、解釈です。また判決における意思決定にどこまで情報技術による支援が可能かということも今後、問題になるでしょう。
日本の警察において、デジタル証拠は管区警察局情報通信部、都道府県警察本部情報通信部情報技術解析課が取り出し・保存し解析がおこなわれ、一部は科学捜査研究所や鑑識においてデジタル・フォレンジック鑑定が行われます。サイバー犯罪捜査は生活安全部サイバー犯罪対策課において行われます。そしてサイバー犯罪を管轄するのは警察庁のサイバー警察局です。ここには情報解析課が設置されており、高度情報技術解析センター、サイバーテロ対策技術室があります。
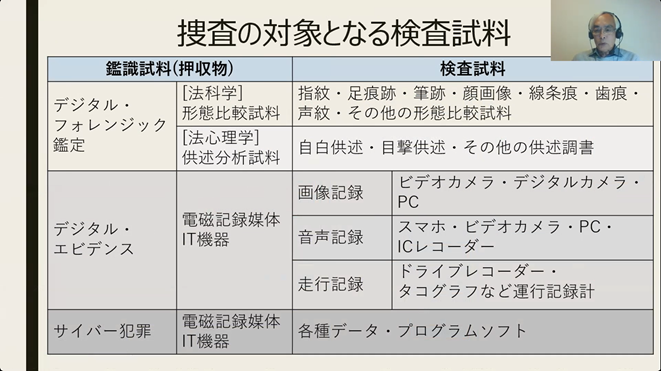
デジタル・フォレンジック鑑定における検査試料
デジタル・フォレンジクスとは
デジタル・フォレンジクスは米国のFBIで最初につかわれた言葉です。デジタル・フォレンジクスとは、デジタル・デバイスに記録された情報の回収と分析調査を行うことです。上記の検査試料を回収・解析・識別判断・考察を行う手続きを経て鑑定結果、検査結果が提出されます。ここで問題になるのは、識別判断における2つの手法の違いです。1つ目は統計的手法という人間が理解し判断する手法で、どのようにその人が理解したのかが分かります(White Box型)。2つ目は機械学習的手法という機械が論理的・経験的に判断する手法で、コンピューターが理解した内容が人間には分かりません(Black Box型)。
ここで機械学習についてみてみます。機械学習ではビッグデータという大容量のデータセットについて、Deep Learning(深層学習)やRandom Forestという計算手順を用いて、データの関係性を顕在化・分類・判別・確率予想・ランク付けを行います。
AIの発展と問題点
人工知能(Artificial Intelligence;AI)は人間と同様の知能を実現しようとする技術ですが、1950~60年ころに第1次ブームがあり、コンピューターを用いて探索・推論を行う研究がスタートしました。第2次ブームは1980年代で、機械学習というある作業を学習・訓練により実行できるAIが開発されました。この段階では人間が論理的判断基準を定義していました。そして第3次ブームは2000年代で、機械が論理的判断基準を定義して深層学習(Deep Learning)によって画像認識・音声認識・異常感知など複雑な問題を処理するようになりました。このようなAIが出現すると、AIとの付き合い方が問題になります。ビックデータをAIで解析することで顔画像による監視システムにも応用可能であり、AIを使った個人情報流出も起こっています。また今後、AIによる判断で差別的ラベルによる選別が行われた場合、その判定や予測の理由は説明ができず、AIに排除される人々が出現するのではないかと危惧されています。そこでEUや米国ではAIを規制する法律が作られました。EUでは2018年に一般データ保護規則が制定され、2021年にAI規制案、米国では2022年にAI権利章典案が提出されています。
デジタル・フォレンジック証拠の信頼性の課題
ここでデジタル・フォレンジック鑑定の課題について考えます。まず鑑定前の試料収集の段階では、電磁記録を回収した時点で消去されてしまう危険性が指摘されています。科学鑑定での試料の全量消費は以前から問題になっていますが、デジタル・フォレンジック鑑定では回収した時点で消えてしまうという課題があります。また、鑑定が始まって、試料がデジタル画像や音声であった場合、撮影や録音の日時が改ざんできてしまうという課題があります。さらにデータを処理することでデータ自体が変質してしまう可能性も指摘されています。また解析する段階にも課題があります。解析ソフトは作成者の考え方(アルゴリズム)に左右されるため、解析ソフトによって結果が異なる可能性があります。また鑑定結果についても、どのようにその結果が得られたのか、人間に理解できないケースがあります。そして鑑定が終了してその鑑定結果を利用する段階にも課題があります。デジタル・フォレンジック証拠の証拠能力・証明力の判断基準の考え方が未確定であるため、裁判への適用には注意が必要です。
司法制度の課題
デジタル・フォレンジック鑑定を日本の司法制度で用いる上でいくつか課題があると考えています。1つ目は「科学の不確実性」です。「科学は確実」と信じる法律家がいる一方、「不確実性をはらんだ科学に基づいていれば、その知見を尊重する必要はない」という極端な見解もあります。デジタル・フォレンジック鑑定の適用限界を理解し、その有効性を判断する必要があるでしょう。2つ目は「専門家証人尋問」です。対立主義は被告人の人権擁護のために必要ですが、デジタル・フォレンジック鑑定の結果を用いる上で、情報学の専門家の参加は不可欠であり、す。専門家への負担軽減のためにも円滑で有意義な尋問方式が必要と考えます。3つ目は「情報社会への対応」です。デジタル・フォレンジックについての解釈・判断は情報学の専門家に丸投げすることになる可能性があります。そうした丸投げを避けるためにも、法学系学生への法科学教育、法律家へのリカレント教育を含めた、法律家の情報技術(IT)リテラシーの向上を目指す必要があるでしょう。
情報社会への変化に応じて科学も司法も変わる必要があります。これまでの法科学の信頼性研究だけではなく、認知心理学によるバイアス研究や統計・情報学による適正化研究が求められます。
アルゴリズムの問題
OCME(ニューヨーク市検視局)法生物学研究所の事例です。ある法科学コンサルタントのコンピューター技師が混合DNA解析ソフト(FST)を開発しました。このソフトを用いて鑑定を行ったところ、DNA鑑定者が気付かないうちに有用なデータが除外され、被告人のDNA型がDNA混合試料に誤って存在してしまうことが判明しました。その結果、FSTの動作の正確性には深刻な疑いが生じ、使用が停止されました。これは、DNAが専門ではない技術コンサルタントがFSTを開発していたことが原因でした。その上、OCME職員はFSTをブラックボックス視しており、十分な検証が行われていませんでした。
次に、筆跡鑑定の解析アルゴリズムについてみてみます。統計学の方法には変位量解析と多変量解析があります。一方、機械学習の方法でも行われています。例えば変位量解析には、水上嘉樹教授が2005年に発表した統計変位分析法とF教授が2011年に発表した幾何学的マッチング残渣法があります。どちらもデータを特徴により分類し、繰り返し処理で最適化した後、問題試料を対照試料と比較識別する方法です。水上方式では個人内変位から平均と分散を抽出します。文字からすべての点を採取し、反復演算で最適な変位量を導出します。筆者識別では変位量の大小で判断します。ズレの大きさが小さければ問題筆跡と同一の人物によるものであると判断します。一方、F教授方式では始筆部・終筆部・転折部を点で抽出します。特徴点採取の判断は検査者が判断しますが、検査者で異なる判断が多い点は除外します。個人内変動の抑制処理についてはヘルマート変換(標準文字に正規化することで大きさ、回転、平行以上の情報が失われる)、射影変換(書きムラと個人内変動の抑制)、幾何的マッチング(同一人の重ね合わせ)によって行われます。筆跡識別では、幾何的マッチング残渣(geometric matching residue;GMR)で行います。幾何的マッチング残渣とは問題筆跡文字と対照筆跡文字の書く特徴点のズレ(距離、pixelで表示)を測定し、数個の文字のGMRの変動の分布について基本統計量(平均値、分散、最大値、最小値)を計算して席分布で表示することで行います。この方式による異同識別精度は3文字の検査で99.8%だと報告されています。しかし、特徴点抽出について検査者で異なる判断が多い点は除外していること、本人筆跡と他人筆跡が単純化されることで、両者の分布が明瞭に分離されることなどにより、重要な個人差が見落とされ、誤判断の危険性がある可能性があると考えられます。このようにアルゴリズムによって分析結果が大きく異なることがあることには注意が必要です。
次回の第2回は、講師に遠山大輔氏(戸田・遠山法律事務所 弁護士)を迎えて「コンピューター犯罪の裁判事例」についてご報告いただきます。
【イベント情報:https://www.ryukoku.ac.jp/nc/event/entry-11628.html】